在数字化时代,图形用户界面(GUI)为我们提供了便捷的操作体验,但随着应用环境的复杂化,传统的操作方式逐渐显露出不足。
最近,微软研究团队发布了一篇名为《Large Language Model-Brained GUI Agents: A Survey》的综述论文,深入探讨了大语言模型(LLM)如何推动GUI智能体的发展,改变我们与计算机互动的方式。
这篇80页的论文由微软的Data, Knowledge, and Intelligence(DKI)团队的成员撰写,他们在GUI智能体的研发中扮演了重要角色。
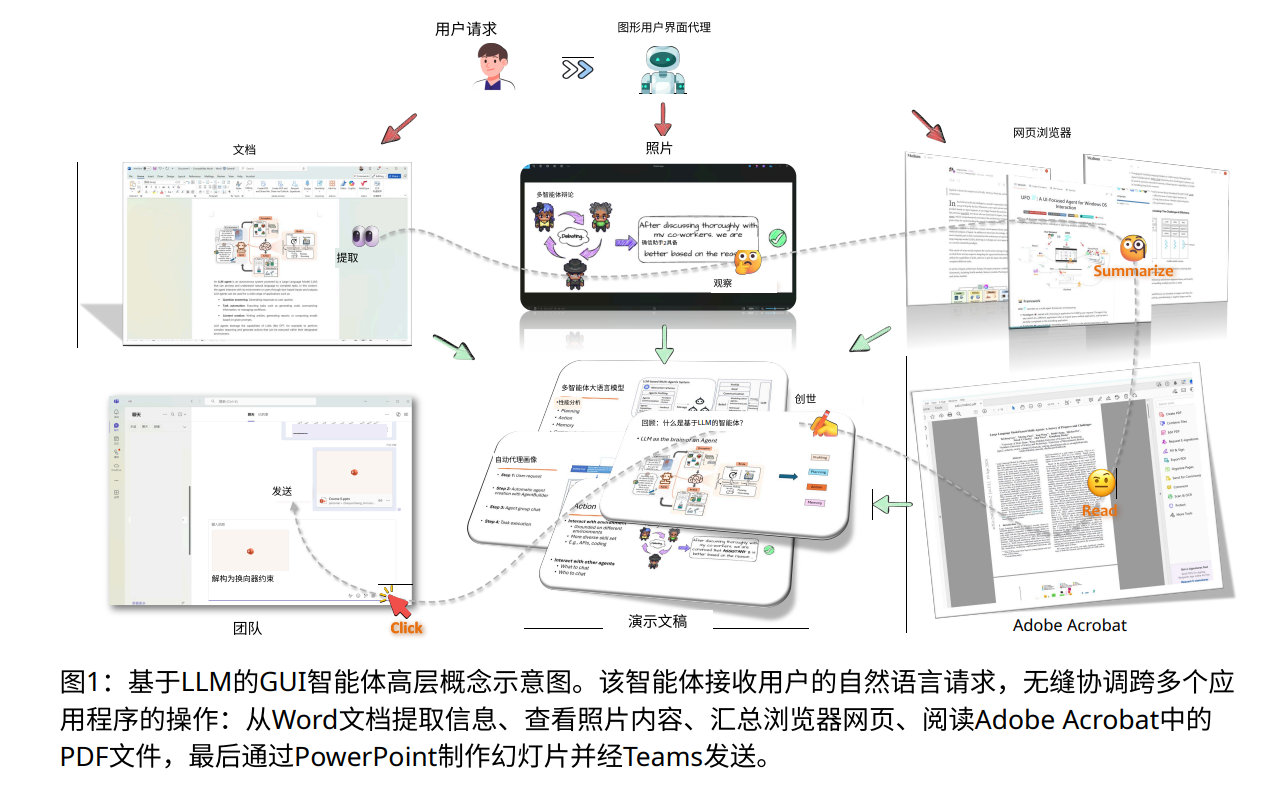
通过结合大语言模型和视觉语言模型,GUI智能体能够理解自然语言指令,并自动执行图形界面的操作。
这一技术的突破,让我们从以往的“点击 + 输入”模式,转向了更加直观的“自然语言 + 智能操作”方式。
过去,GUI自动化主要依赖脚本化和规则驱动的方法,这些方法在面对频繁变化的界面时显得力不从心。
比如,传统的脚本工具如Selenium和AutoIt虽然在稳定的环境中表现良好,但一旦界面更新,脚本就可能失效。
而规则驱动的方法则缺乏灵活性,难以应对复杂的工作流程。
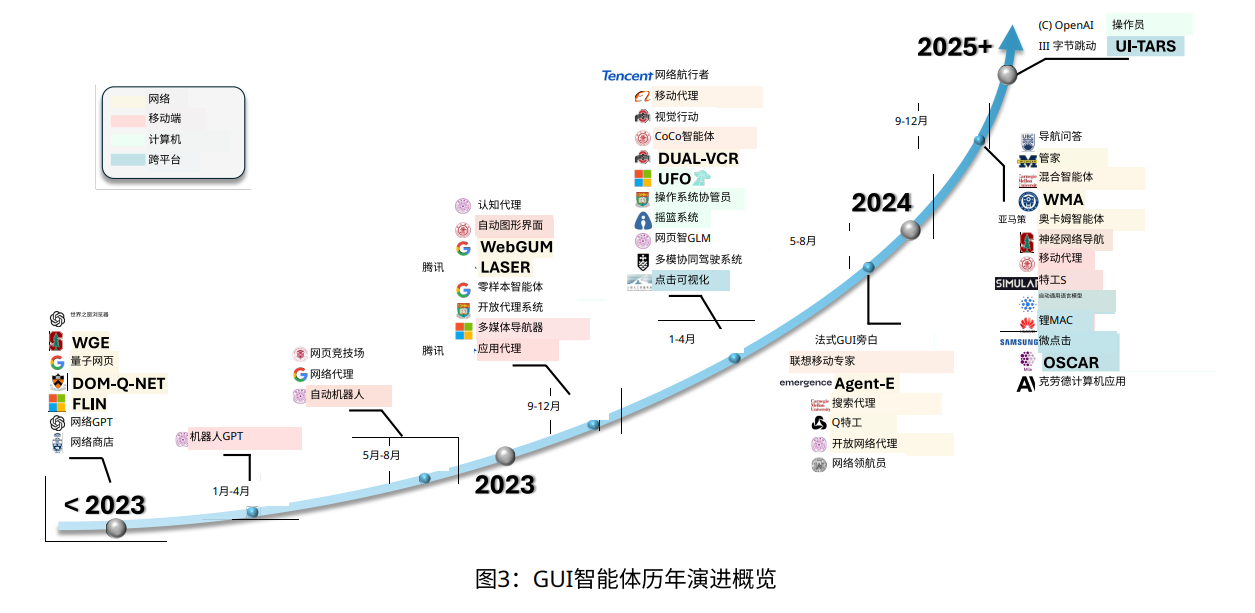
因此,如何让自动化系统理解网页内容、适应不同设备的多样化界面,以及在多步骤任务中保持上下文的连贯性,成为了亟待解决的挑战。
微软的综述指出,大语言模型在这些方面展现了巨大的潜力。
它们不仅能够理解用户的自然语言指令,还能将其转化为一系列可执行的操作步骤。
通过多步推理和任务分解,智能体能够完成复杂的工作流程。
此外,结合视觉理解技术,智能体可以分析GUI界面的布局,理解各个元素的含义,从而在动态环境中执行精准操作。
这种智能体不仅能响应指令,还能根据上下文灵活调整策略,使得操作更加高效。
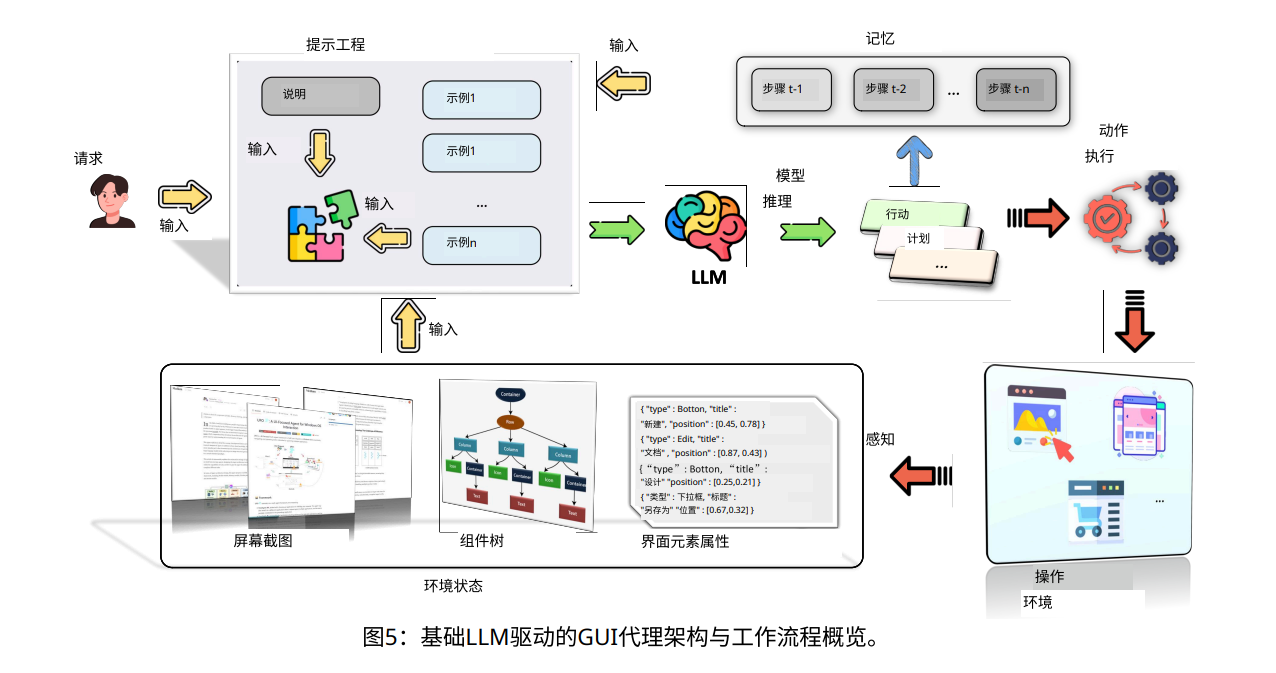
论文还详细介绍了GUI智能体的核心架构,包括操作环境感知、提示工程、模型推理、操作执行和记忆机制等。
通过捕获界面信息、构建输入提示并利用大语言模型生成操作计划,智能体能够在不同平台上执行任务。
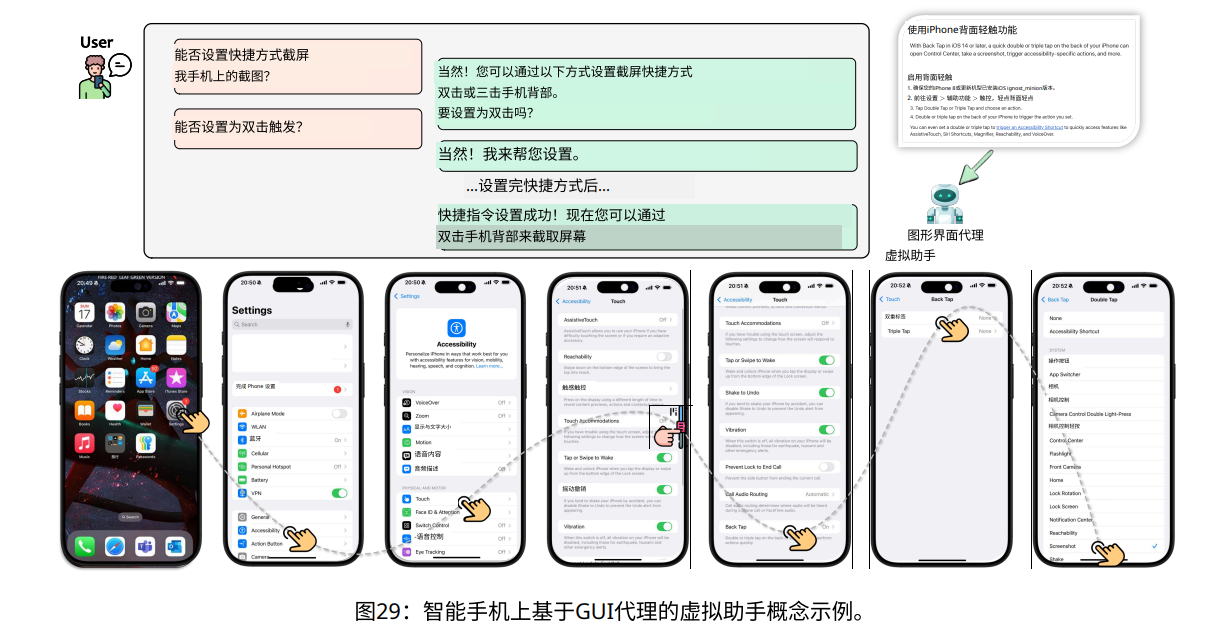
随着技术的不断发展,GUI智能体在软件测试、智能助手等领域的应用也越来越广泛。
比如,在软件测试中,智能体可以通过自然语言描述生成测试用例,自动导航界面,捕捉潜在缺陷,大幅提高测试效率。
而在日常操作中,智能助手能够跨越桌面和移动设备,以自然语言指令完成各种任务,极大地提升了用户体验。