图1:LightGen:通过知识蒸馏和直接偏好优化实现高效图像生成
在最近的技术进展中,香港科技大学的Harry Yang教授团队与Everlyn AI等机构联合推出了一个名为LightGen的高效图像生成模型。
这个模型的最大亮点在于它能够在仅使用8张GPU的情况下,快速生成高质量的图像,几乎达到了当前最先进技术的水平(SOTA)。
更重要的是,LightGen是开源的,这意味着更多的研究者和开发者可以利用这个工具,推动相关领域的发展。

图 2:概述了 LightGen 在图像生成、零样本修复和资源使用方面的功能。(第一行)以多种分辨率生成的图像 ( 512 × 512 和 1024 × 1024 ) 说明了 LightGen 的可扩展性。(第二行)零镜头修复结果展示了 LightGen 固有的编辑能力。(第三排)与最先进的模型相比,LightGen 的资源消耗大幅减少数据集大小、模型参数和 GPU 小时数,这表明在不牺牲性能的情况下显著降低了成本。
LightGen的核心在于它采用了知识蒸馏(KD)和直接偏好优化(DPO)这两种策略。
这些策略帮助团队显著压缩了大规模图像生成模型的训练流程,降低了对数据规模和计算资源的需求。
通过这种方式,LightGen不仅在资源受限的环境下展现了出色的性能,还在高质量图像生成任务中与现有的最先进模型相媲美。
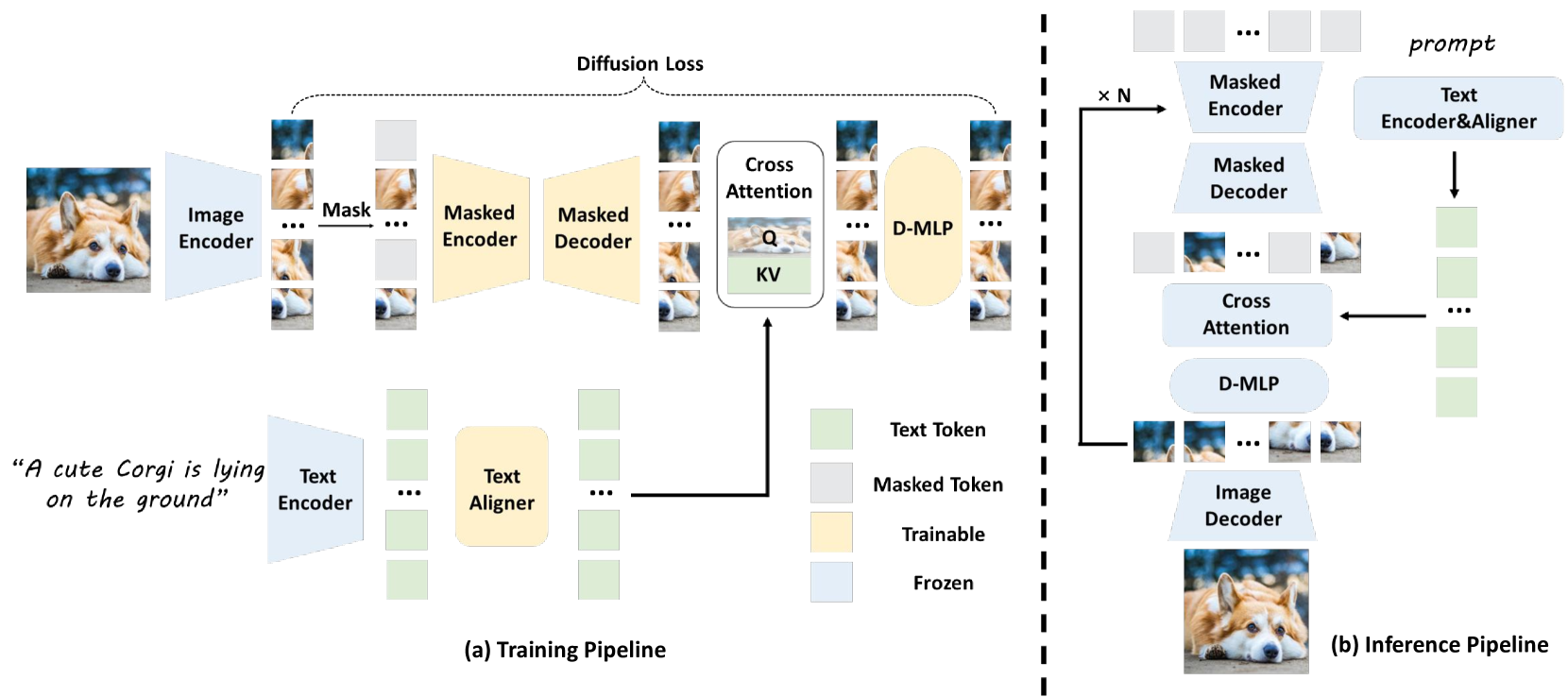
图 3:LightGen 高效预训练概述。(a) 训练:图像通过预先训练的分词器编码为标记,而来自 T5 编码器的文本嵌入则由可训练的对准器进行提炼。掩码自动编码器使用文本标记作为查询/值,使用图像标记作为交叉注意的键,然后使用扩散 MLP (D-MLP) 进行细化。(b) 推理:对 Token 进行预测和迭代优化𝑁步骤,然后由 Image Tokenizer 解码以生成最终图像。
具体来说,LightGen在图像生成的过程中,首先利用当前最先进的文本到图像(T2I)模型生成了一套丰富语义的高质量合成图像数据集。
这些图像具有较高的视觉多样性,并且配有由大型多模态语言模型生成的文本标注,确保了训练数据在文本和图像两个维度上的多样性。
接下来,团队引入了直接偏好优化技术,作为后处理手段,进一步提升生成图像的细节和空间关系的准确性。
实验结果显示,LightGen在不同分辨率下的图像生成任务中,表现均接近或超过了现有的最先进模型。
尤其是在512×512的分辨率下,LightGen的整体性能分数达到了0.62,几乎超越了所有其他方法。
值得一提的是,加入DPO方法后,模型在位置准确性和高频细节方面的表现得到了稳定提升,充分体现了DPO在解决合成数据缺陷上的有效性。

图 4:说明 LightGen 的 DPO 后处理。
LightGen的成功不仅在于其高效的训练过程,还在于它的设计理念。
团队认为,数据的多样性比数据的规模更为重要,因此在选择预训练数据时,最终选择了200万张图像作为最优的数据规模。
这一选择使得LightGen在训练效率和生成质量之间找到了良好的平衡。
如果你想深入了解LightGen的细节,可以访问项目的GitHub页面。
同时,相关的论文也可以在这里找到:LightGen论文。