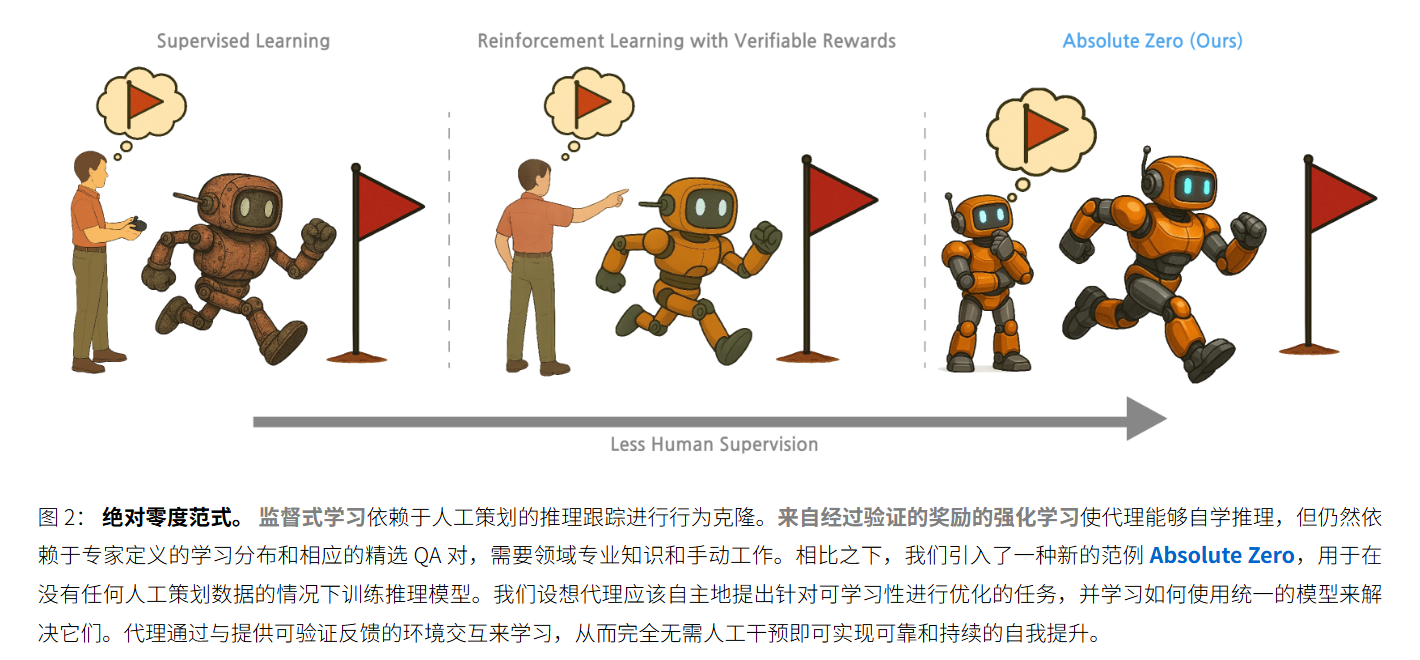
 近日,清华大学、北京通用人工智能研究院与宾夕法尼亚州立大学研究团队联合提出 “绝对零”(Absolute Zero)训练法,无需外部数据即可通过大模型自我博弈解锁推理能力。
近日,清华大学、北京通用人工智能研究院与宾夕法尼亚州立大学研究团队联合提出 “绝对零”(Absolute Zero)训练法,无需外部数据即可通过大模型自我博弈解锁推理能力。
该方法让模型同时扮演 “任务生成者” 与 “问题解决者”,将推理任务转化为可执行的代码三元组(程序、输入、输出),通过溯因、演绎、归纳三类任务的自主生成与求解循环迭代,在代码执行器验证任务有效性后优化模型。
实验显示,经该方法训练的 Qwen-2.5 系列模型在编程任务 HumanEval + 等数据集及数学推理 MATH500 等数据集上准确率显著提升,且性能提升与模型规模正相关。相关成果引发 Reddit 热议,被认为是大模型自我进化的重要突破。
以下是论文链接:
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
科技咖是一个专注于AI和科技产品的平台,提供AI论文、AI报告、AI大模型、AI机器人等内容,展示全球最新的AI技术和应用。在这里,你可以了解到最新的AI动态,发现最有创意的AI产品。

 晋公网安备14010702074479号
晋公网安备14010702074479号