在数字化时代,视频内容的创作与编辑需求越来越高,尤其是在电影制作和社交媒体的影响下,高质量的视频编辑技术成为了行业的核心竞争力之一。
然而,视频重打光这一技术却一直是个难题。
视频重打光是指对视频中的光照条件进行调整和优化,传统的方法通常需要高昂的训练成本和大量的数据,这让很多人感到无从下手。

不过,现在有了一个突破性的技术——Light-A-Video。
这项由上海交通大学和上海人工智能实验室联合研发的技术,彻底改变了视频重打光的方式。
最令人兴奋的是,Light-A-Video是一个无需训练的零样本视频重打光方法。
也就是说,你不需要花费时间和资源去训练模型,就可以直接生成高质量、时序一致的重打光视频。
这是因为它充分利用了预训练的图像重打光模型(如IC-Light)和视频扩散模型(如AnimateDiff和CogVideoX),结合了创新的Consistent Light Attention(CLA)模块和Progressive Light Fusion(PLF)策略,能够有效地进行光照控制。
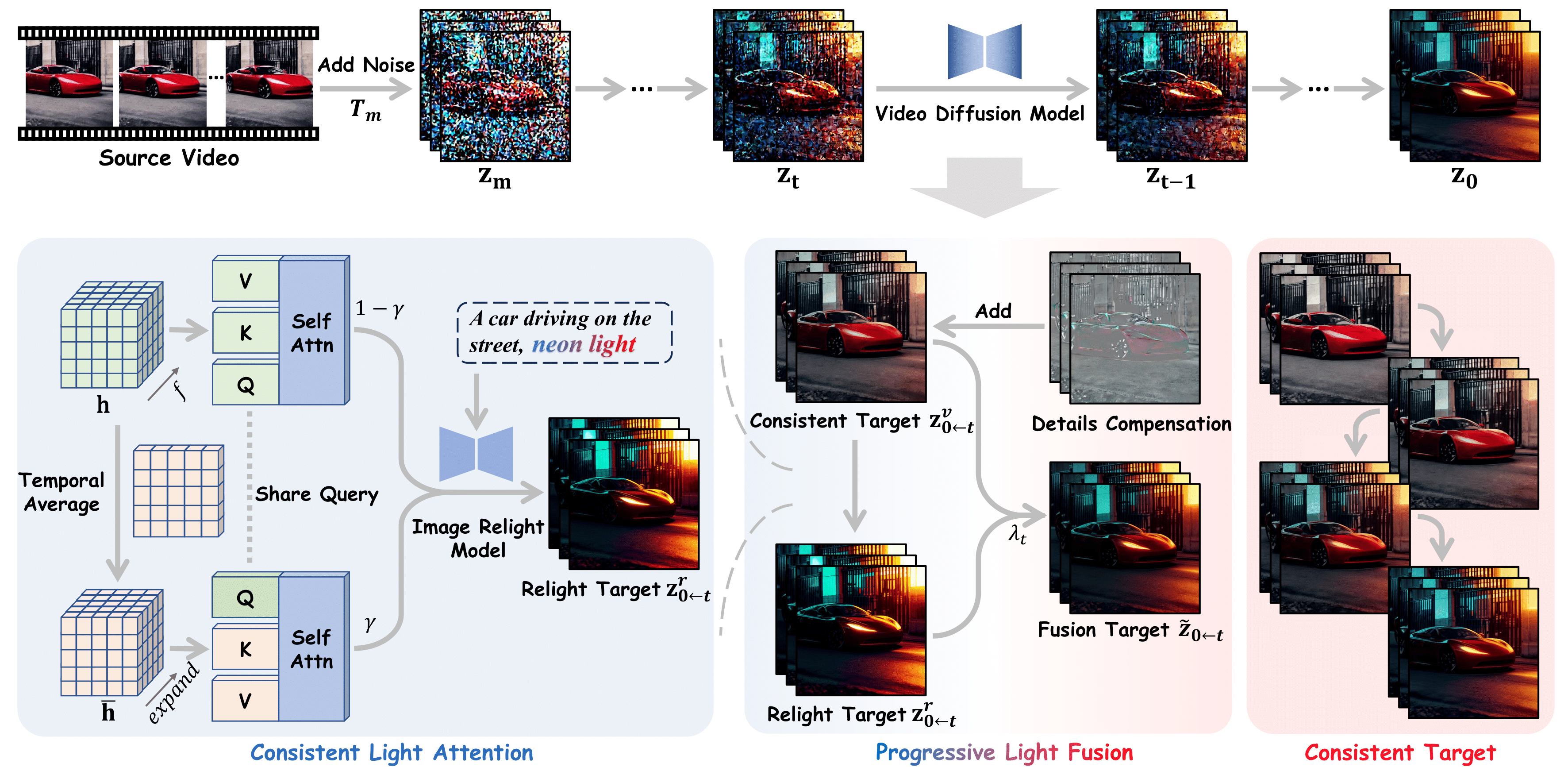
Light-A-Video的优势在于其高效性和灵活性。
首先,它是首个无需训练的视频重打光模型,直接利用现有的预训练模型,避免了传统方法中的高昂训练成本和数据稀缺问题。
这使得视频重打光的效率和扩展性大大提高。
此外,Light-A-Video还支持对完整视频和前景序列的重打光,甚至可以根据文字描述生成背景,具有很强的适用性。
在技术层面,Light-A-Video的CLA模块通过增强跨帧的交互,确保背景光源的稳定性,减少了光照不一致导致的闪烁问题。

而PLF策略则通过渐进式的光照融合,将重打光效果与原始视频外观进行平滑过渡,确保了视频的时间连贯性。
实验结果显示,Light-A-Video在多个评估指标上均优于现有的方法,特别是在动作保留方面,能够在保持原视频外观的基础上实现高质量的重打光效果。如果你想深入了解这个项目,可以访问它的项目主页 Light-A-Video 和查看相关论文地址。