在当今信息爆炸的时代,用户对信息检索的需求日益多样化,尤其是在图文结合的场景中,传统的检索方式已经无法满足人们的需求。
智源研究院最近推出的BGE-VL多模态向量模型,正是为了解决这一问题而生。
BGE-VL通过结合图像和文本,能够更精准地理解用户的查询意图,从而提供更相关的检索结果。
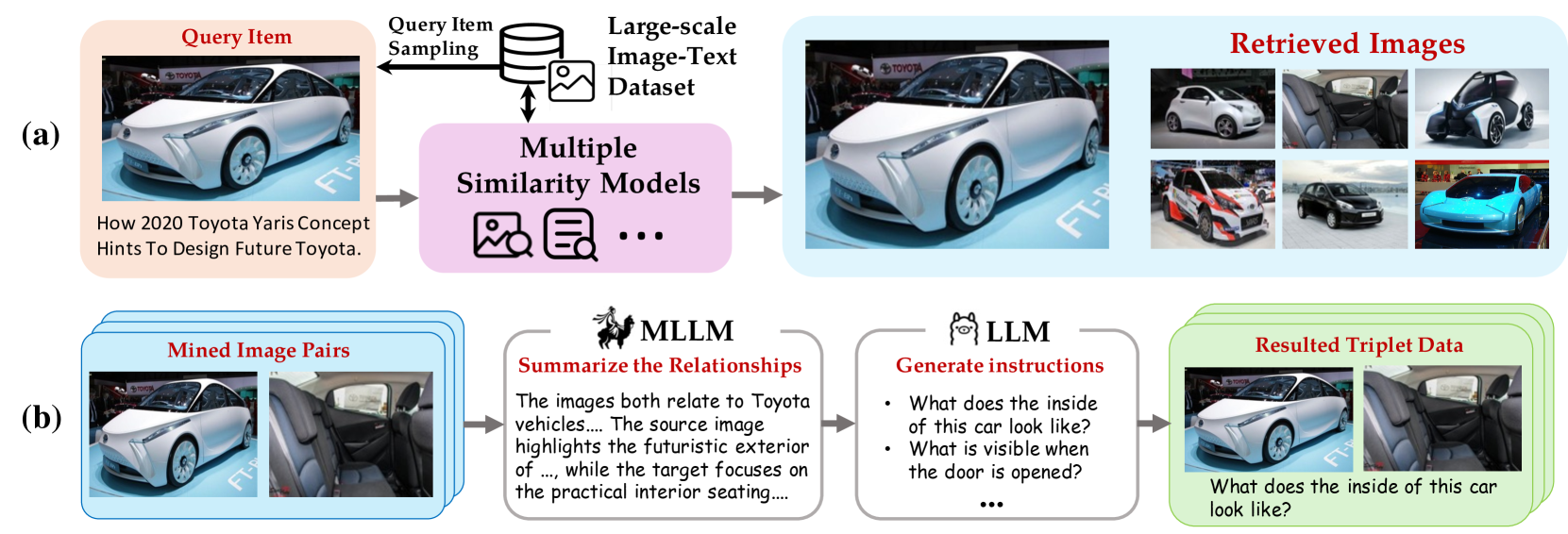
BGE-VL的核心在于其训练所依赖的大规模合成数据集MegaPairs。
这个数据集不仅数量庞大,包含了2600万条样本,而且其数据质量也远超传统的多模态数据。
MegaPairs的构建过程是非常创新的,智源团队通过挖掘现有的大规模图像数据集,利用多种相似度模型来生成多样的图像对,然后再通过开源的多模态大模型和大语言模型来合成检索指令。
这种方法的好处在于,它大幅降低了人工标注的需求,使得数据的获取更加高效和多样化。
在多模态检索的应用场景中,用户可能会上传一张汽车的照片,并希望获取该车型的详细信息。
BGE-VL能够有效理解这张图像与文本指令之间的关系,从而提供用户所需的信息。
这种能力的提升得益于MegaPairs提供的高质量数据,BGE-VL在多个主流的多模态检索基准上都取得了最佳的性能表现。

团队在测试BGE-VL的过程中,发现其在零样本学习的能力上也表现得相当出色。
尽管MegaPairs数据集中并不包含所有的任务类型,BGE-VL依然能够在不同的任务上展现出良好的泛化能力。
此外,在组合图像检索的评测中,BGE-VL同样刷新了现有的基准,显著超越了包括谷歌MagicLens和英伟达MM-Embed等多个对比模型。
这一切都表明,BGE-VL不仅在技术上具有领先优势,更在实际应用中展现了其强大的潜力。

未来,智源团队计划继续探索MegaPairs与更多多模态检索场景的结合,致力于打造一个更为全面和通用的多模态检索器。
这样的发展将为用户提供更为便捷和高效的信息获取方式,推动多模态检索技术的进一步普及。
如果你对BGE-VL感兴趣,想要深入了解其技术细节,可以访问项目主页和论文地址,获取更多的信息和资源。
项目主页在这里:GitHub – MegaPairs,论文地址在这里:arXiv – BGE-VL。